(Work done with Ruth Rosenholtz, Nadja Schinkel-Bielefeld, and Martin Wattenberg)
For over a century, Gestalt theorists have known that human beings organize visual information according to concrete and reliable principles. These “Gestalt laws” have been well-studied, and include such well known principles as grouping by proximity, grouping by similarity, and the law of good continuation. However, while these principles seem to accurately describe many aspects of human visual behavior, little is known about how these principles come about from a computational perspective. Without a robust computational model which recreates these principles implicitly or explicitly, the Gestalt laws carry little or no predictive power, and can give us little insight into more general human visual behavior.
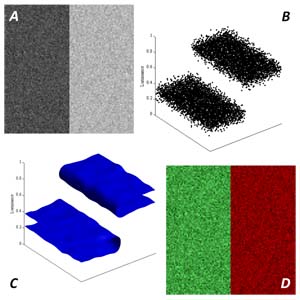
To address this gap, Ruth Rosenholtz and I developed a computational framework to implement the Gestalt principles of proximity and similarity. In our model, depicted at right, the pixels of an image are mapped to a new, higher-dimensional space, which contains not only the two spatial dimensions of the original image, but also one or more feature dimensions, corresponding to features relative to the organization of the image. In this example, such a feature is luminance (L); and mapping each pixel in Image A into x-y-L space yields two easily discernible clusters of points (Figure B). In essence, our framework translates the problem of grouping into a clustering problem. The regions of higher density in this higher dimensional space (Figure C) thus correspond to segments of the original image defined by both proximity and similarity in the given feature. Projecting these regions down yields an organization of the image consistent with classic Gestalt principles (Figure D).
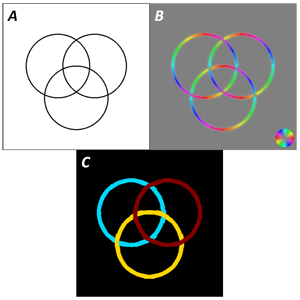
This model provides a robust, intuitive implementation of Gestalt principles which previously merely descriptive. However, it is not limited to only grouping by luminance similarity – any feature which can be represented by a low-dimensional space and mapped across the full image can be used to perform grouping. For example, if we measure the dominant orientation at every point, we can perform grouping by orientation similarity; minor modifications allow us to perform grouping by good continuation. The figure at the left shows one example of our good-continuation model in action.
In Figure A, we see three circles, all of equal luminance but easily discernible by the principle of good continuation. Figure B depicts the dominant orientation at each pixel, along with the magnitudes of those orientations. By mapping thexe pixels into x-y-θ space, where θ represents dominant orientation, we are able to separate and cluster the related oriented segments, identifying the three visual groups (Figure C).




